
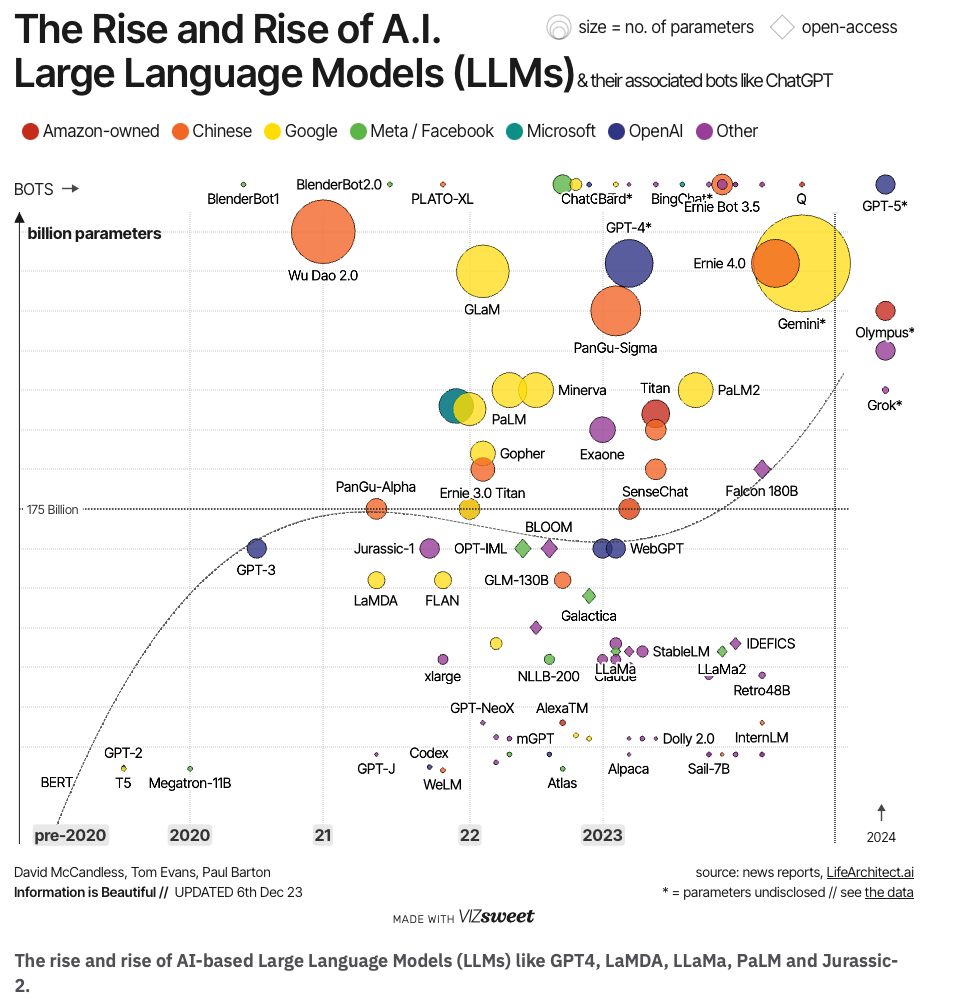
La era de la inteligencia artificial está marcada por el rápido desarrollo de los Modelos de Lenguaje de Gran Escala (LLMs) como GPT-4, LaMDA, LLaMa, PaLM y Jurassic-2. Estos modelos no solo están cambiando la forma en que interactuamos con la tecnología, sino que también están presentando desafíos y oportunidades únicas para los profesionales técnicos, especialmente los Data Scientists. En este artículo, profundizaremos en los aspectos técnicos de estos modelos y exploraremos cómo están modelando el futuro de la IA.
Entendiendo las Redes Neuronales Transformadoras
Un componente clave en el desarrollo de los LLMs modernos son las redes neuronales transformadoras. Estas redes, popularizadas por el modelo Transformer de Google en 2017, han revolucionado el campo del procesamiento del lenguaje natural. Se caracterizan por su capacidad para manejar secuencias de datos de gran longitud, lo que las hace ideales para tareas de comprensión y generación de lenguaje.
Características Principales
- Mecanismo de Atención: Lo que distingue a los Transformes es su mecanismo de atención, que permite al modelo enfocarse en diferentes partes de la entrada a medida que procesa la información. Esto mejora la capacidad del modelo para establecer relaciones y contextos complejos en el texto.
- Paralelismo y Escalabilidad: A diferencia de las arquitecturas recurrentes, las transformadoras pueden procesar secuencias de datos en paralelo, lo que aumenta significativamente la velocidad y eficiencia del entrenamiento.
- Flexibilidad: Son adecuadas para una amplia gama de tareas de PLN (Procesamiento del Lenguaje Natural), desde la traducción automática hasta la generación de texto, gracias a su capacidad para aprender patrones complejos y variados en los datos.
Impacto en los LLMs
Los modelos como GPT-4, LaMDA y otros utilizan variantes de la arquitectura Transformer, lo que les permite manejar grandes volúmenes de datos y aprender de manera más efectiva. Esto ha llevado a avances significativos en la capacidad de estos modelos para entender y generar lenguaje natural de manera coherente y contextual.
Aspectos Técnicos de los LLMs
Arquitecturas y Algoritmos
Los LLMs como GPT-4 y PaLM se basan en arquitecturas de redes neuronales de transformadores, que han demostrado ser excepcionalmente eficaces para tareas de procesamiento del lenguaje. Estas arquitecturas permiten que los modelos manejen secuencias largas de datos, lo cual es crucial para comprender y generar lenguaje natural.
Capacitación y Aprendizaje
La capacitación de estos modelos requiere una cantidad significativa de datos. Por ejemplo, GPT-4 se entrenó con un dataset que incluye textos de libros, artículos y sitios web, abarcando una amplia gama de temas. Esto plantea interesantes preguntas sobre la selección de datos y la representación.
Aplicaciones Prácticas
En el ámbito profesional, los LLMs se están utilizando para automatizar tareas de PLN (Procesamiento de Lenguaje Natural) como la traducción de idiomas, la generación de contenido y el análisis de sentimientos. Su capacidad para entender y generar lenguaje humano los hace ideales para aplicaciones en atención al cliente, educación y análisis de datos.
Desafíos en la Implementación de LLMs
Sesgo y Equidad
Un área de especial interés para los Data Scientists es el sesgo inherente en los datos de entrenamiento. ¿Cómo podemos garantizar que estos modelos sean justos y no perpetúen prejuicios existentes?
Eficiencia y Escalabilidad
A medida que aumenta el tamaño de los modelos, también lo hace su consumo de recursos. Explorar la eficiencia en el entrenamiento y la inferencia de estos modelos es un desafío clave.
Interoperabilidad y Personalización
Integrar LLMs en sistemas existentes y personalizarlos para necesidades específicas es otro área de interés. ¿Cómo pueden los Data Scientists utilizar estos modelos para resolver problemas únicos en sus campos?
Preguntas para la Comunidad
Me gustaría escuchar sus opiniones y experiencias:
- ¿Cómo están utilizando los LLMs en sus proyectos actuales?
- ¿Qué estrategias han encontrado efectivas para mitigar el sesgo en los modelos de lenguaje?
- ¿Cuáles son sus enfoques para mejorar la eficiencia y la personalización de los LLMs?
Referencias y Lecturas Adicionales
- GPT-4 Technical Paper
- Google’s LaMDA: Language Models for Dialogue Applications
- The rise and rise of AI-based Large Language Models (LLMs) like GPT4, LaMDA, LLaMa, PaLM and Jurassic-2
Espero que este artículo proporcione una comprensión profunda de los LLMs y sus implicaciones en el campo de la ciencia de datos. Estoy deseando escuchar sus opiniones y discusiones en los comentarios.
