
POST HERE
Music scores are beautiful antiquities of human expression that continue to be held in high regard and admired by those who long to conjure up sounds of past compositions, those who wish to preserve their musical creations for others, and appreciators of symbolic visual vocabularies in general. Music scores are also a creation of an elite class, the reading of which requires literacy through training that is not readily available to all, including those who play music beautifully but by ear. Furthermore, music scores may present themselves still yet curious artifacts of analysis to those with no music training whatsoever albeit a high level of interest in analyzing its aesthetic representation.
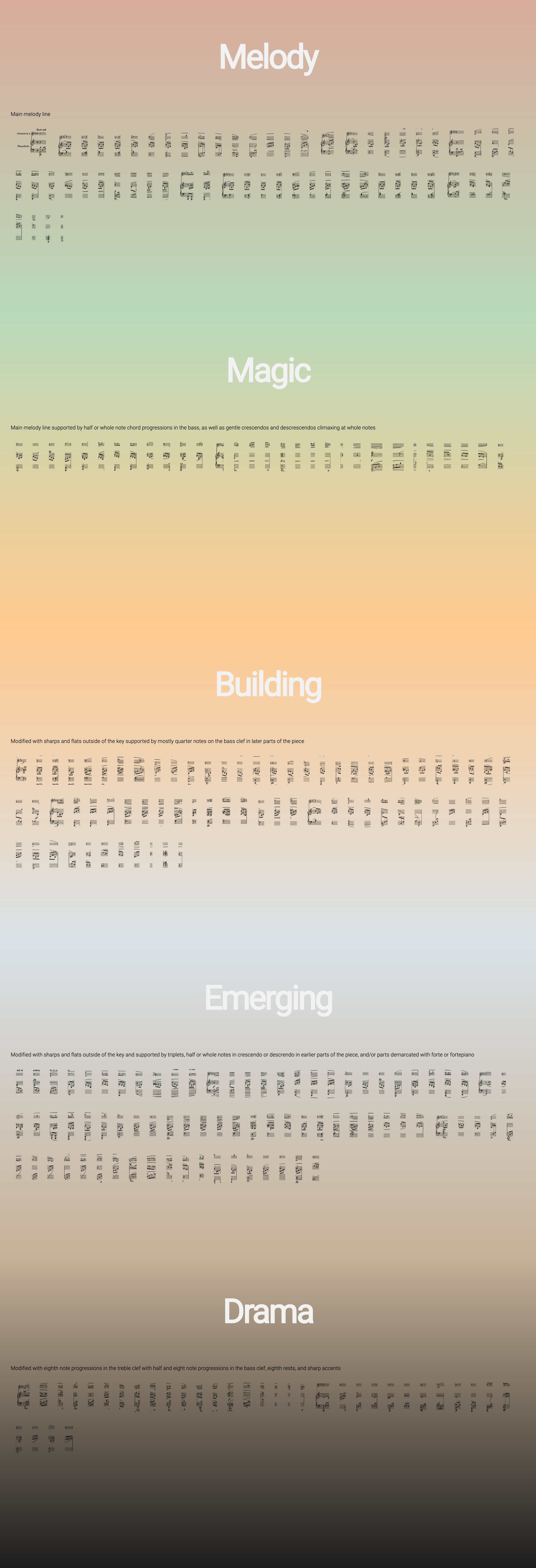
What can we do to make the literacy of music scores more accessible and inclusive to all, to share the beauty of how a composer crafts intention throughout a piece and varies movement and mood?
One proposal: we might begin by color-coding music scores.
Grouping musical movements in this way is beneficial for revealing patterns that can be otherwise very difficult to articulate. This is a 3-step guide to help designers and developers color code music scores by key, tempo, tone and feeling through musical notation and sequential progression.
Getting started
Download or clone the tutorial example files:
https://github.com/3milychu/ml_color_music_score
What you’ll need:
I. Prepare your Music Score for Clustering
Obtain an electronic copy of the music score
You will need an electronic copy of the music score you intend to create a visual color score for. For best results, your electronic copy should be free of unappealing dark or white-washed scan marks and of balanced orientation (the pages should avoid slants to make it easier for you to visually slice between desired phrases). You can also use the tutorial score images as provided here.


Slice your music score by the desired level of color code grouping
Once you have your electronic copy, you will now need to slice it per the atomic level you wish to analyze similarity by. For example, if you wish to see the piece grouped by the similarity between beats, each beat should be sliced into its own image file.
A simple way to do is with a graphical handling software such as Illustrator, Sketch, etc. that allows you to quickly create neatly aligned canvases around each beat. Then, you can simply export all canvases to a designated location. You will want to follow an unfettered and straightforward naming convention for each beat (i.e. 1.png, 2.png, 3.png, etc.)
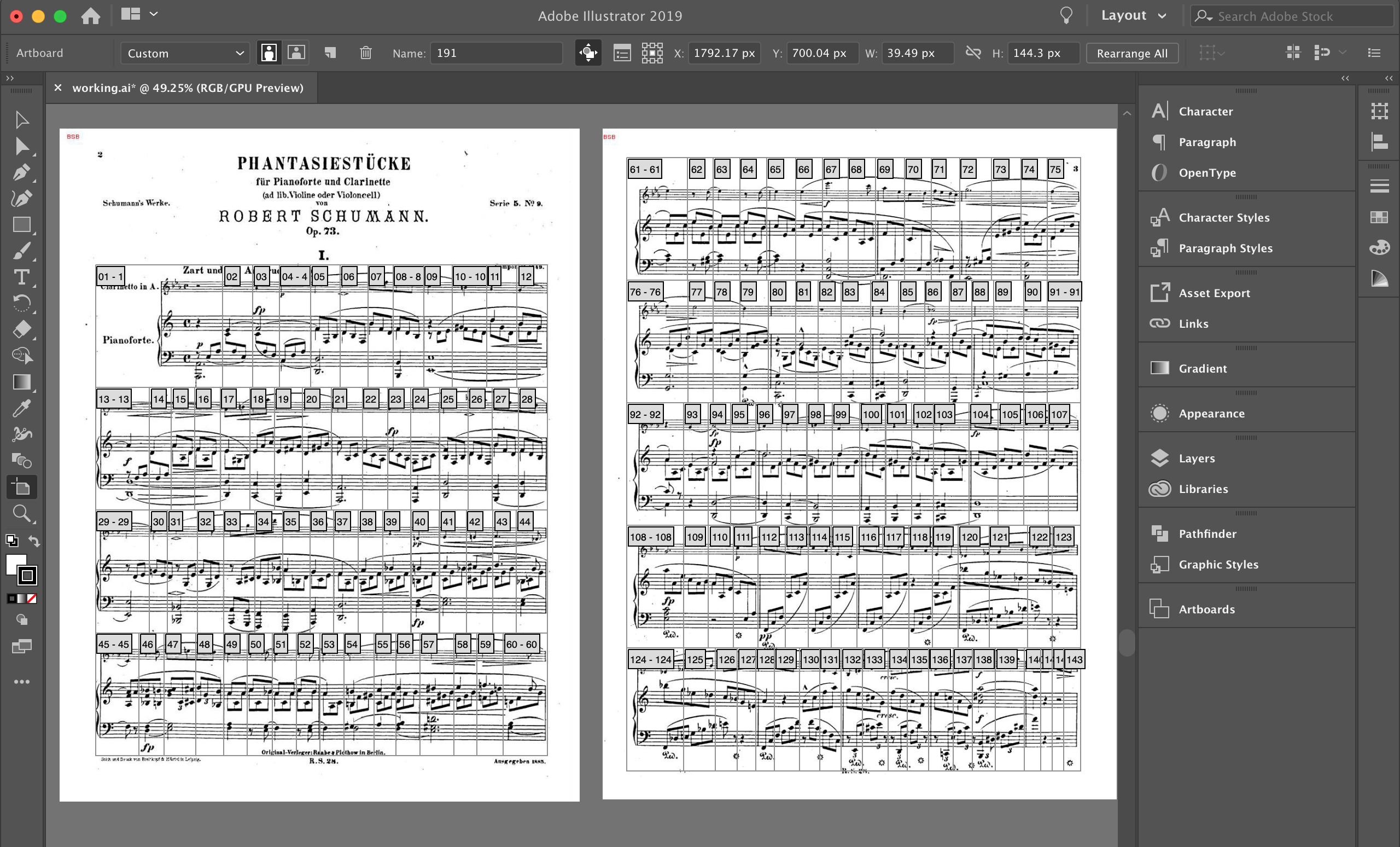
Nice! We’ve prepped our music score for clustering. But wait, what is clustering and how does this help the process?
Clustering is a data science technique for taking selected information from a set of objects and grouping them by similarity. There are a few ways you can do this. One way, which is what we will be using here, is by running the data through a model called k-means.
The k-means model is unsupervised — something we say to mean there are no examples of absolute right or wrong answers given to the machine, the groupings are formed to the best of its knowledge based on all the information intentionally given (hence why it is very important to give it the cleanest and most efficient information). The process we just went through heads the beginning of our effort to distill complex information contained by music scores into minimal information that is clean, clear, and readable by the machine.
Goal: Complex → Simple Information
Step 2: Run your Music Score Data through the Machine Learning Model
The next step in the process is to turn our music score images into a data format that the machine learning model we will be using will appreciate (numbers).
First, open the kmeans-model notebook from the github tutorial repository. Then, construct a dataframe of all your image filenames:

Next, append any important metadata you have that can add to the analysis:

We now select the image transformation technique which we believe best accentuates musical notation information and refine until satisfied:
The image transformation technique selected focuses on edge detection. Successful edge detection can be simply understood as outlining targeted objects or shapes in an image and discarding what does not help us identify those essential objects or shapes. Since we will be converting the transformed images into an array of numbers, we want the array of numbers to be as minimal as possible (Ideally think 1 for where a mark takes place and 0 where no marks take place). The idea is that this will allow us to remove unnecessary noise while preserving the most important features of an image, and the machine will learn what makes one image with certain shapes similar to another. See a nice introductory handout to the goals of edge detection here.
Various edge detectors are provided in the sample tutorial code; the tutorial ends up using the final edge detector in the image processing function. Feel free to play around and pass through the edge detection method you see fit.

We arrive at the moment which we pass through the machine-readable music score data pertinent to our case and cluster it through our machine learning model (k-means):
We’ve arrived at this moment because we’ve ideally distilled our images into minimal transformations of essential shapes through edge detection. Then, we took those feature-accentuated images and created arrays out of them. Our working dataframe now has columns identifying which image we’re working with and an array of that image transformed into numbers. Then, we’ve added any important metadata we think is pertinent to the analysis (such as measure number and beat number). These are the features that the k-means will use to group each item by similarity.
K-means Model Parameters
How do we choose our number of clusters, and do we refine parameters after viewing results iteratively to elicit a comprehensible nod of approval from your music friend? Here are some questions we may consider:
- How often does the melody change dramatically overall?
- How often does the key change throughout the piece?
- How often does the tempo change throughout the piece?
- How are modifications distributed throughout the piece?

The results will look something like this, where the ‘labels’ column contains the cluster assigned to that individual beat:
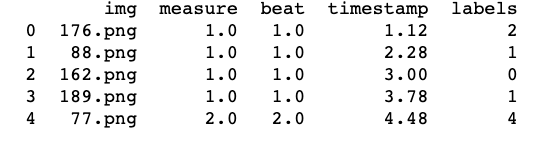
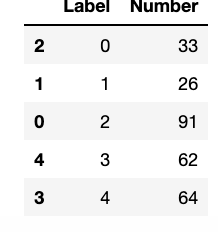
Finally, to make our cluster information usable for data visualization, let’s output to .json or .csv format

Step 3: Visualize your Music Score Data
You can visualize your music score data however you like based on the tool and technique of your choice. In this tutorial, we will use a simple html/css/javascript template I created. Find the ‘results.html’ file in the github tutorial repo or access it here.
This template is very simple. There is a “vis” div container to hold the visualization. You will modify the script to iterate through the number of images you are working with. The function getScore() will get your JSON and append a container with an image and a color bar for each object (each beat in our case). You can modify styles in the template to change the color of label+# by class.
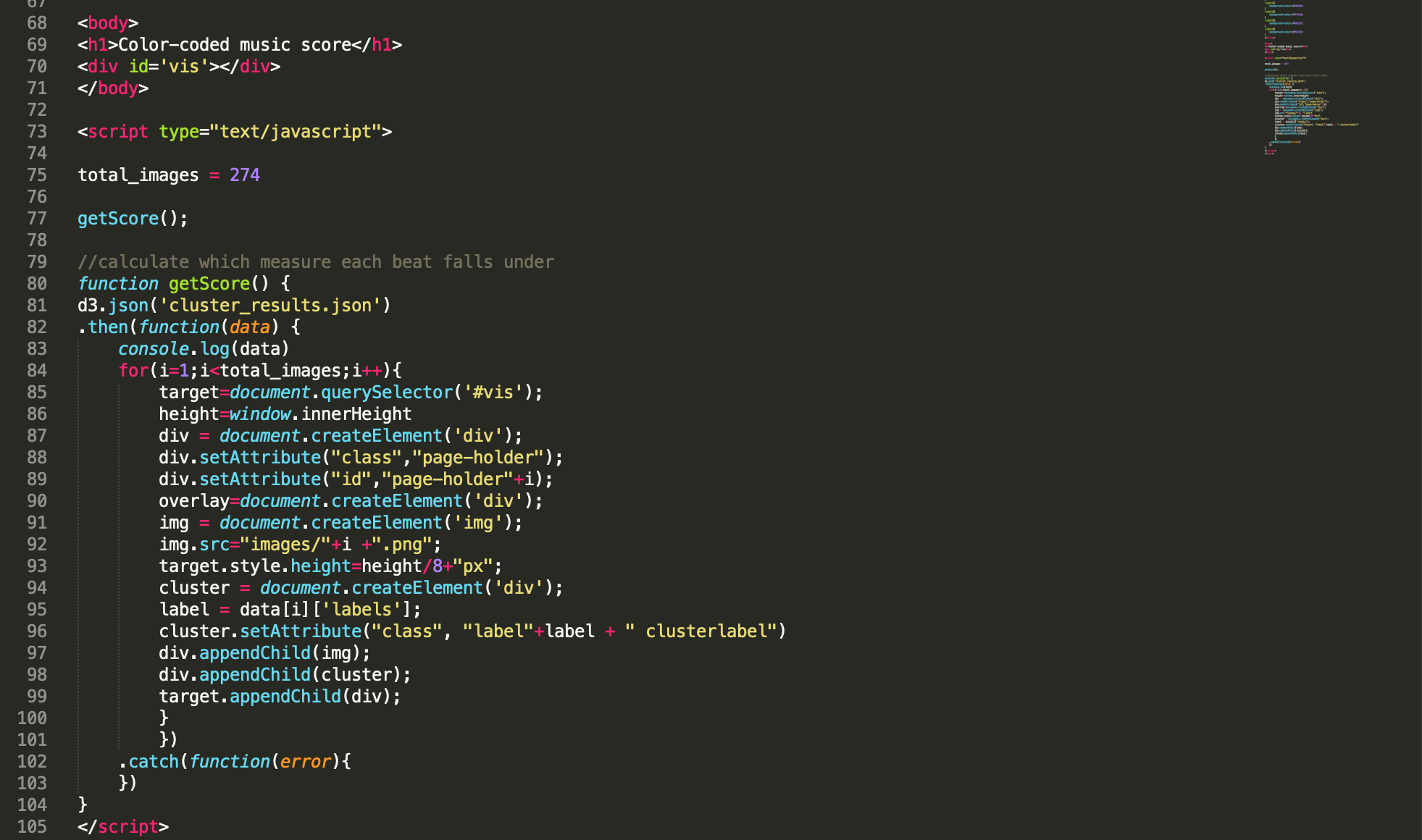
What this template will give you:

For presentation purposes, you can also use the cluster analysis template shown ‘cluster-analysis.html’ in the repo or access here, where you can showcase the information you selected to cluster your music score, name your clusters, and display all image beat information belonging to a cluster interactively.
El Fin
If you wish to learn more about the k-means model used to better understand how to set parameters and interpret findings, here are some classic readings and resources:
- Quick overview:
https://stanford.edu/~cpiech/cs221/handouts/kmeans.html - Exploratory simulation: https://stanford.edu/class/ee103/visualizations/kmeans/kmeans.html
- More fun ways to extend analysis of music scores to additional features (do you actually have recording of a performance perhaps?):
https://musicinformationretrieval.com/kmeans.html
Limitations and Notes
Some immediate ways to improve the method described above:
- Test a dataset of images similar but not equal to the music score images you use, validating that the image processing method used predicts or “sees” musical notation the best (in the meantime, I have to admit this is an educated hypothesis from experience).
- Confirm that musical notation is indeed the most minimal and efficient way to procure many musical attributes associated with a piece (tempo, tonality, expression). If not, use the alternatively most minimal and efficient way to procure that information.
- Run this experiment on a wide variety of music scores! Rectify inaccurate assumptions and refine your modeling techniques based on experience.
Have fun!
